论文名称:[CCS 23'] ProvG-Searcher: A Graph Representation Learning Approach for Efficient Provenance Graph Search
论文链接:https://arxiv.org/pdf/2309.03647v1
代码链接:https://github.com/EnesAltinisik/ProvG-Searcher
阅读笔记
主要解决的问题
在大量历史系统日志存储库中高效搜索已知攻击行为来进行威胁狩猎
网络攻击日益复杂和数量庞大,仅依赖组织内部可用的检测工具已不再可行。因此,威胁猎人必须不断扫描威胁情报提供的新的威胁行为描述,并假设相同的攻击者可能会绕过他们组织的安全控制。
场景引入
威胁猎人发现针对一个与他们所在行业相同的组织的消息最新攻击情报。在这种情况下,安全人员会假设攻击者可能已经渗透了他们的系统,并在系统日志中搜索潜在的入侵痕迹。在溯源分析的背景下,这需要将外部情报的威胁行为转换为可以在系统级溯源图中搜索的查询。
这个问题可以被看作是图包含(子图匹配)问题的一个实例。
示例场景: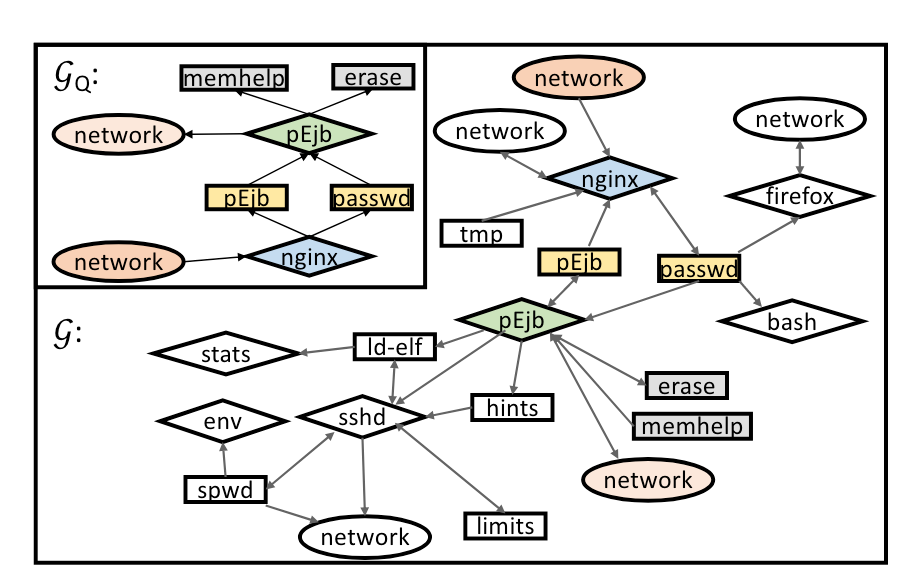
现在获取到了一个描述了一个对nginx
Web服务器进行攻击的威胁情报报告:通过下载恶意载荷并执行以获取root权限。威胁猎手利用这些信息创建一个查询图
目标:在系统级溯源图
这篇论文就是这个问题的一个解决方案,并开发了一个名为ProvG-Searcher的系统,在庞大的溯源图中高效准确地识别匹配给定的查询图。
基于子图匹配匹配方法的溯源图检测
子图匹配问题涉及确定查询图在结构上和关键特征上是否同构于较大图的子图,这是图分析中的一个基本问题。然而,精确子图匹配被认为是NP完全的。因此,基于组合方法的精确方法无法解决大规模实例。
为了在合理的时间范围内执行子图匹配,已经提出了几种近似解决方案。
较早的不精确子图匹配方法通常依赖启发式方法来判断节点更好的对齐,或将离散优化问题转化为连续问题。
近年来,图神经网络在图表示学习方面取得了显著成功,几种基于学习的近似子图匹配方法的开发,性能优越。
这些方法的核心是学习一个嵌入函数,将每个图映射到封装其关键特征的嵌入向量中。然后,在这个连续的向量空间中评估两个图嵌入之间的子图关系。
基于子图匹配方法检测的难点:
溯源图节点和边的数量多,平均节点度高,搜索和学习图计算成本过高
日志粒度粗阻碍系统实体之间准确追踪信息和控制流,导致节点之间出现错误连接 -> 基于图之间节点对齐的搜索方法很大程度上不可行
将基于GNNs的基于学习的方法应用到大型图中会引入进一步的复杂性。GNNs通过一系列消息传递迭代进行计算,在此过程中,节点从相邻节点收集数据以更新自己的信息。然后所有节点的更新信息被汇总在一起以创建一个图级表示。在这种情况下,增加模型深度超过几层(即迭代次数)以更有效地捕捉关系会导致GNN的接受域呈指数级的扩展,从而导致由于过度平滑而导致表达能力减弱 。
为了提高溯源图分析的效率,目前的研究提出了一些简化溯源图的方法:
- 实体剪枝:
- 去除冗余语义:
- 行为抽象:
- 缓解依赖爆炸
这些数据减少方法主要集中在识别异常交互并保留取证的可追踪性上。然而,它们通常无法达到保持足够完整性以支持对更一般图模式的搜索的目标。
先前基于假设的威胁狩猎技术难点:
- 高效搜索
- 查询图的生成
通过学习搜索溯源图的挑战
挑战 #1:图的规模
从计算机收集的审计日志可能会在较短时间内产生具有非常多节点和边的衍生图。GNN的表达能力由其容量确定,一般以神经网络的宽度和深度来表达,即GNN的嵌入大小和层数。另外,对于大图增加模型深度,即GNN的层数,通常会导致相邻节点数量呈指数扩展。这意味着当学习子图关系时,必须通过子图采样等方法进行限制GNN的感受野。
挑战 #2:高度节点
溯源图中的节点平均度数可能很高。
一部分是由于依赖爆炸问题,长时间运行的进程与许多其他系统实体互动会出现作为图上高度连接节点的情况。在GNN中的计算通过多次消息传递迭代进行,节点从相邻邻居聚合信息以更新其信息。对于高度节点,这种聚合步骤可能会抑制有用的特征,导致表达能力下降,原因是众所周知的过度平滑行为,在经过几轮消息传递后节点嵌入变得无信息 ,尤其是对于不经常发生的系统行为而言。
需要平衡系统行为的表示。
挑战 #3: 保留事件的时间顺序
在溯源图中,边表示事件的时间顺序。忽略时间信息实质上会引入系统实体之间的虚假信息流。图神经网络中的计算包括在每个节点创建以描述信息传递和聚合结构的计算图。在图创建过程中,可以通过强制从根到叶执行时间顺序来整合时间信息。
然而,在实践中,为了避免重复创建这些计算图所带来的计算开销,使用递归邻域聚合方案。该方案无法保持边之间的因果关系,因为所有节点同时从其邻居那里聚合信息。此外,需要考虑到行为可能不会明确包含所描绘事件之间的时间信息。
因此,必须利用时间信息,使子图关系不明确依赖于它。
挑战 #4: 查询中的语义鸿沟
查询行为与在溯源图中观察到的之间表达的程度可能不匹配。
查询图可能不一定传达系统级别的交互及其所有细节。例如,查询图可能显示浏览器或应用程序进程作为攻击向量的一部分。然而,在审计日志中,这个进程可能对应于主要进程的克隆或由启动器进程生成的另一个进程来处理任务,而这可能不是查询的一部分。此外,缺少或未记录的事件或额外交互的包含可能导致查询的行为仅部分匹配溯源图。
因此,学习到的表示必须对这些变化提供一定程度的鲁棒性。
挑战 #5: 设定学习目标
为了促进模型的泛化,需要从相同的数据分布中获取训练和测试样本。这种一致性使模型能够有效地学习数据中的潜在模式和关系,增强其识别新的和未见数据中的子图关系的能力。在威胁猎杀的背景下,预计查询图将显示与观察到的攻击行为具有强烈关联。
因此,需要调整模型的训练过程以反映这些行为。
系统设计和方法
问题定义
一个图
给定一个目标图和一个查询图,图蕴含问题的解决方案涉及在目标中检测每个查询实例。由于在规模为溯源图的图上进行精确子图匹配是不可行的,本文采用一种近似匹配方法来进行子图预测。
通过提取每个进程节点
给定ego-graphs
因此,编码器必须结合归纳偏置来有效表示子图关系,同时学习一种映射,其中子图预测函数
本文采用了一个子图嵌入函数,有效地解决了这两个问题。
利用顺序嵌入的概念,旨在将实体之间的排序属性编码到目标表示空间中。顺序嵌入具体的建模了具有反对称性和偏序传递性的层次关系,这些关系是子图关系固有的。为了嵌入函数𝜂,利用了归纳图神经网络并应用了顺序嵌入技术。使能够学习一个几何结构化的嵌入空间,有效地表示子图间的关系。
在查询执行状态下,编码器𝜂独立地应用于查询图
为了确定一个图是否为另一个图的子图,可以简单检查
表示结合所有满足子图关系的ego-graphs 和查询ego-graphs
是一个计算 和查询图 交集的评分函数
系统架构

- 离线嵌入和在线预测
图创建
从审计日志构建溯源图表示主体(eg. 进程)和客体(eg. 进程,文件,网络套接字)之间的交互
图简化:(挑战#1和#4)
采用PROVDETECTOR和Deephunter的方法处理,只保留进程、文件、网络和注册表对象,维护读、写和修改属性事件。为所有进程clone、fork或者execute事件。同时为了避免冗余删除open和cloase事件(因为他们在读或写事件之前或者之后)
拓展了通用的图简化方法:
线程处理
应用程序通常使用线程提高性能和可扩展性,但是查询图可能不会
为了保证图的一致性 => 将线程合并到父进程中

为了捕获远程服务器行为随时间的变化
=> 采用Dependence-Preserving Data Compaction for Scalable Forensic Analysis的方法,在10分钟的时间窗口内将每个远程IP和端口视为一个不同的源
查询图和溯源图中实现系统实体和交互的一致性表示
例如,查询图中的浏览器进程可能对应于溯源图中的多个进程之一,如Firefox、Chrome或Safari。同样,两个具有相同名称的文件在不同应用程序的上下文中可能关联不同的功能。为了避免这种歧义,本文对除网络对象外的所有系统实体使用基于系统目录的抽象,以提供每个实体的一致描述。
网络对象根据其源IP、目的IP和目的端口进行抽象。每个IP地址根据其用途被分类为public、private或local,端口则根据是否小于1024而分类为reserved或user。

抽象系统实体不仅有助于揭示图中的重复模式,还允许进一步减少图的复杂性。当同一抽象类别的对象节点(如文件、网络套接字和注册表项)通过共享事件类型连接到单一主体(进程)节点时,将这些节点合并为具有相同对象抽象的一个节点。
为了在去重过程中保持因果关系,当flow是进程->对象(如写入或属性修改)时,保留第一个事件的时间戳;如果flow是对象->进程,保留最后一个事件的时间戳。
由于这些节点只连接到一个进程,这个过程保留了节点之间的因果关系。
缓解依赖爆炸(挑战#2和#3):
提取ego-graphs实施了两种策略:
利用可用的事件时间戳信息对flow施加时间限制
将特定节点指定为sink节点
图分区(挑战#1):
进程是唯一活跃的系统实体,采用以进程为中心的溯源图视图间接涵盖了涉及其他实体的所有关系
提取ego-graph,使用动态规划算法

保持行为的图简化(挑战#1和#4):
生成的ego-graph可能仍包含冗余信息。
例如,考虑一个用户进程写入了数百个 var 目录文件的ego-graph,这些文件可能出现在不同的上下文中。然而,涉及该用户进程的给定查询很可能只与这些上下文中的一个相关。因此,从搜索的角度来看,用户进程写入 var 目录比跟踪写入的文件数量更具信息性。
此外,由于重复事件可能在信息聚合步骤中占主导地位,GNN 可能主要学习这些重复行为而忽略不太频繁的行为。为了避免对观察到的系统行为的抑制,有必要在每个ego-graph中识别和消除重复模式。
为实现这一点,本文通过行为保持的图简化来去除冗余信息。
通过迭代标签传播捕捉每个节点在不同深度的局部图结构。
将节点版本折叠回原始节点上(尽管这样会失去版本控制的好处,但在创建自我图时保持时间依赖性确保了每个自我图中仅包含相关的系统实体,从而消除了所有与无关系统实体的虚假交互)。通过聚合邻居节点的哈希值来计算每个节点的哈希值。对于每个节点,节点的抽象类别被分配为其0跳哈希值,然后使用以下公式从入边和出边累积邻居节点的哈希值:
和 表示节点n在前向和后向l跳距离上的hash值 hash()函数是SHA-256函数
对于给定输入节点n,使用函数
检索所有与源节点相连的传入边 返回所有出度边及其目标节点 集合函数
按顺序返回输入中唯一的字符串 从ego-graph的锚节点开始执行保留行为缩减。在每个深度 𝑙,确定相邻节点的所有唯一 (𝑘 − 𝑙) 哈希值,并为每个唯一的哈希值选择一个节点。这些选定的节点形成该深度的唯一节点集合。在最多 𝑘 个深度上重复这个过程,并获得整个ego-graph的唯一节点集。利用这些唯一节点,创建一个保留原始行为的缩减自我图。

[---未完待续---]